AI 技术的发展和新的软硬件接口抽象为云原生基础设施带来了新的挑战和机遇,以面向特定领域体系结构处理器为代表的新架构能够提供更高的性能,更低的成本和更优的能效。
2022 年 11 月 30 日 OpenAI 公司推出了智能聊天机器人 ChatGPT,在发布后的 2 个月内用户数量就突破 1 亿,成为史上用户增长最快速的现象级应用。ChatGPT 表现出的对文本的超凡理解力和生成能力,让工业界对 AGI 从学术研究走进实际的商业应用有了前所未有的信心,各类基于 Transformer 架构的 AIGC 大模型应用如雨后春笋,国内也出现了百模大战的态势,更进一步出现了 Stable Diffusion 和 Sora 等多模态大模型。
在近几年的大模型研究和工程实践中,业界发现模型的训练数据、参数量和计算量越大,模型的效果越好,模型规模与模型效果呈现显著的正相关,虽然学术界存在争议,但大模型的 Scaling Law 仍然是业界的基本共识。
为应对大模型对算力、存储(带宽、容量)需求,必须把大量加速卡和服务器节点通过高速总线和网络连接起来,利用节点内总线Scale-Up)和节点间网络(Scale-Out)的层次化扩展能力,构建大规模 AI集群以提供充足的算力供应,随着模型尺寸的持续增长,AI 集群的规模也越来越大。
典型的 AI 集群具有两个或三个网络平面及一个高速总线平面,分别是:前端网络平面,用于集群管理和 AI 作业的调度发放;后端网络平面,用于扩展多 AI 服务器节点,通过高性能网络 Infiniband 或以太网把不同节点的 GPU/NPU 卡通过 RDMA 协议连通起来,主要用于模型参数的数据同步;
存储网络,通过专用的存储网卡和交换机将训练节点和存储设备连接起来,用于训练数据读取和模型快照(Checkpoint)存取;高速总线(Scale-Up link)平面,通过高带宽高可靠的片间总线(如:PCIe/NVlink 等)将节点内加速卡互联起来,用于大模型训推过程中的梯度更新等数据同步。
报告获取:公众号『报告智库』回复数字“1”




















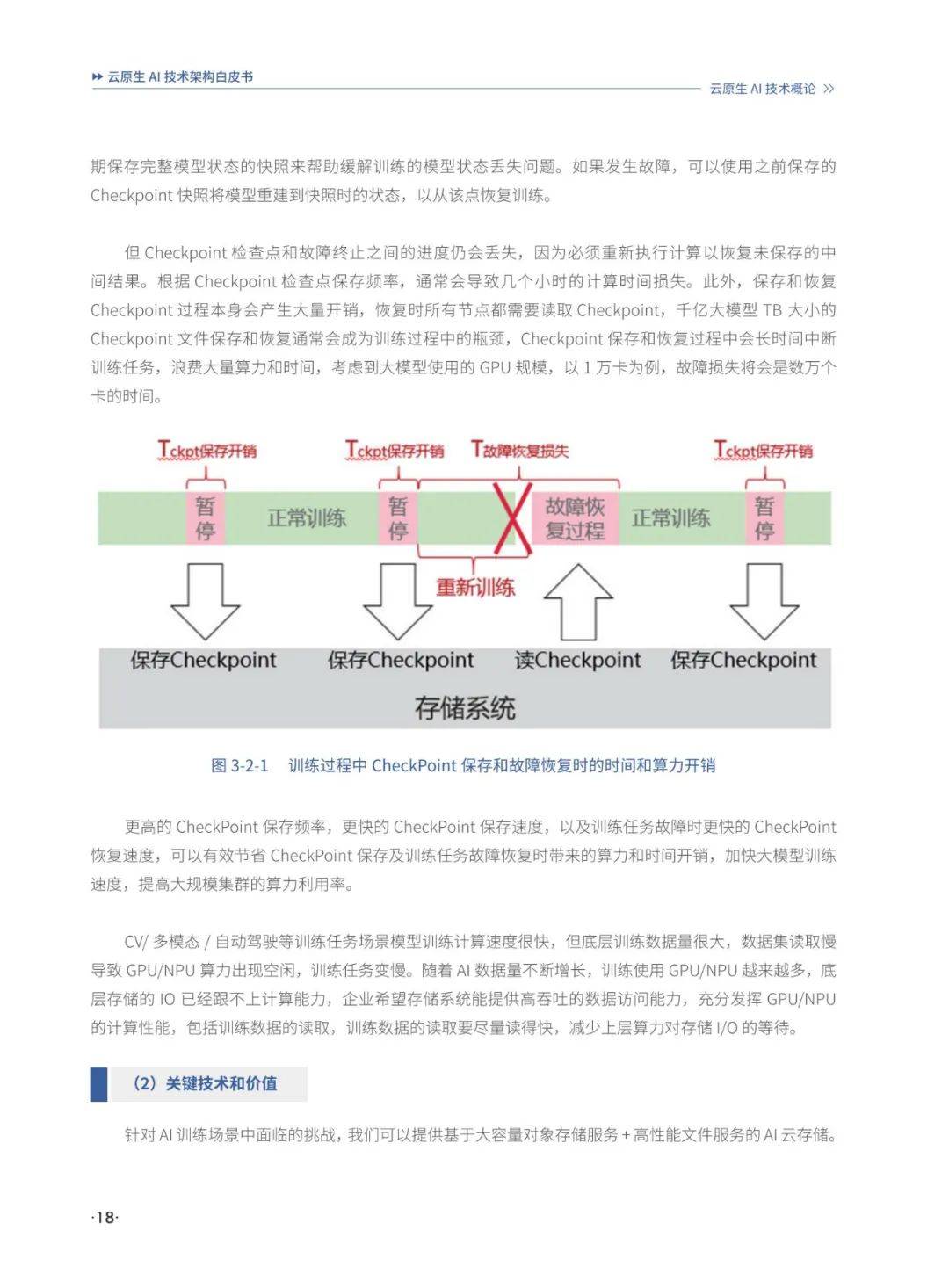

 报告完整版 已分享到『报告智库』知识星球,本社群每年更新优质报告20000+,营销策划方案每周更新,一年365本电子书、读书笔记及各行业精品资料下载,? 点击这里 即可加入!
报告完整版 已分享到『报告智库』知识星球,本社群每年更新优质报告20000+,营销策划方案每周更新,一年365本电子书、读书笔记及各行业精品资料下载,? 点击这里 即可加入!本文地址:https://www.baogaozhiku.com/13685.html

