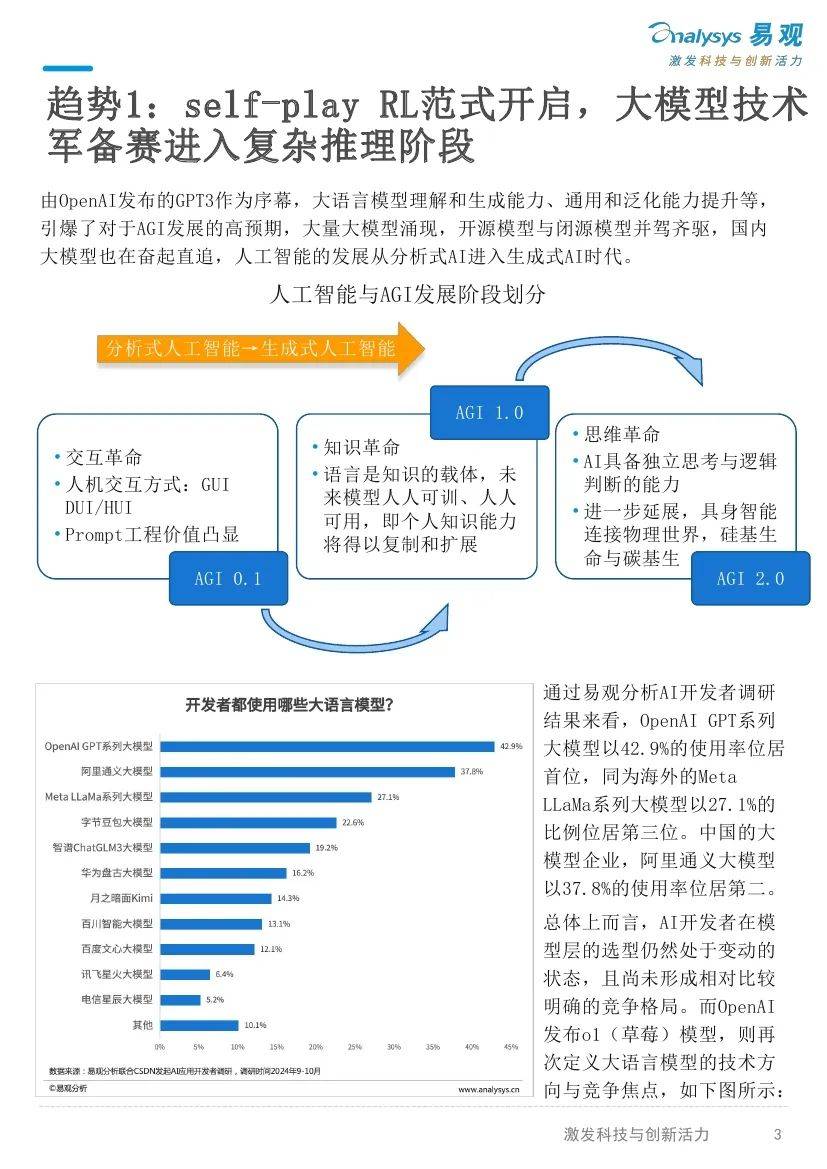
由0penA1发布的GPT3作为序幕,大语言模型理解和生成能力、通用和泛化能力提升等,引爆了对于AGI发展的高预期,大量大模型涌现,开源型与闭源模型并驾齐驱,国内大模型也在奋起直追,人工智能的发展从分析式AI进入生成式AI时代。
通过易观分析AI开发者调研结果来看,0penAIGPT系列大模型以42.9%的使用率位居首位,同为海外的MetaLLaMa系列大模型以27.1%的比例位居第三位。中国的大模型企业,阿里通义大模型以37.8%的使用率位居第二。
总体上而言,AI开发者在模型层的选型仍然处于变动的状态,且尚未形成相对比较明确的竞争格局。而0penA1发布o1(草莓)模型,则再次定义大语言模型的技术方向与竞争焦点。
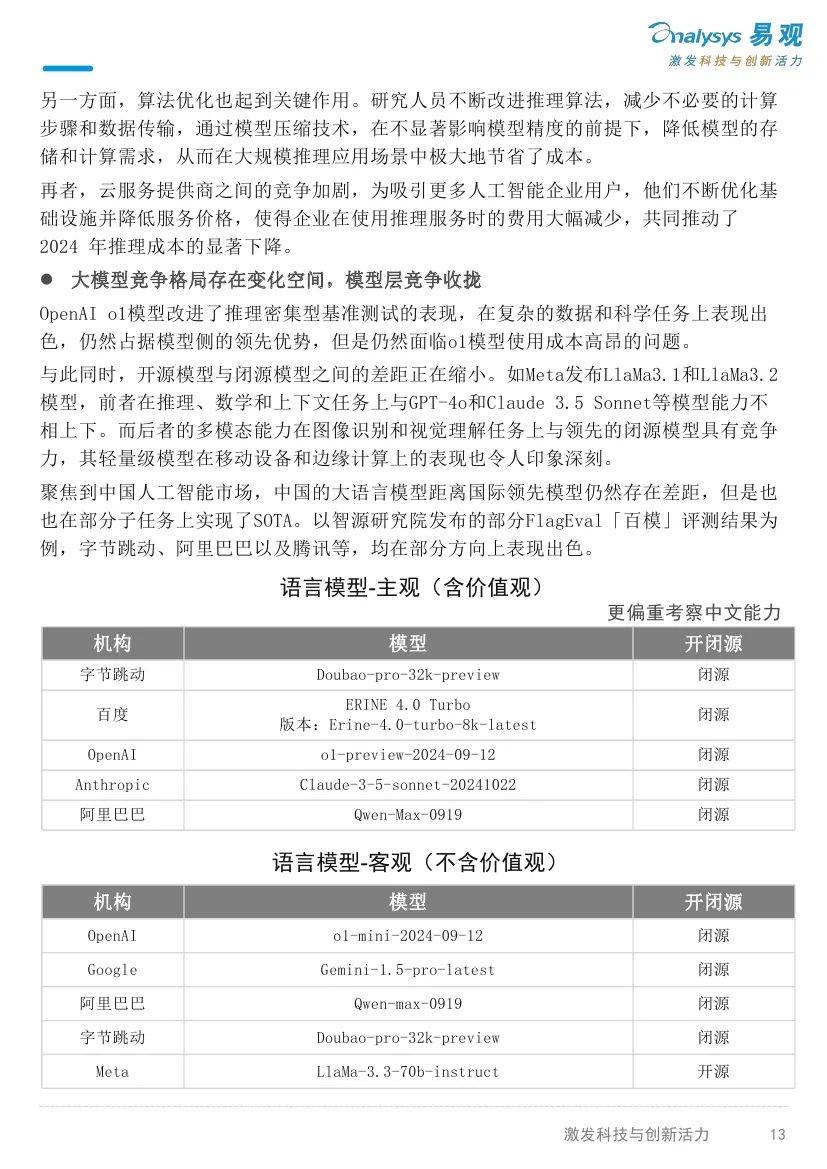
与以往的模型相比,0penAI01聚焦于优化推理过程,在复杂的科学、编程和数学等任务中的表现显著提升。它能够像人类一样进行深入思考、逐步推导,这对于解决需要深度逻辑推理的问题具有重大意义,突破了对大型语言模型能力的传统认知,为人工智能在复杂任务处理上开辟了新的道路。
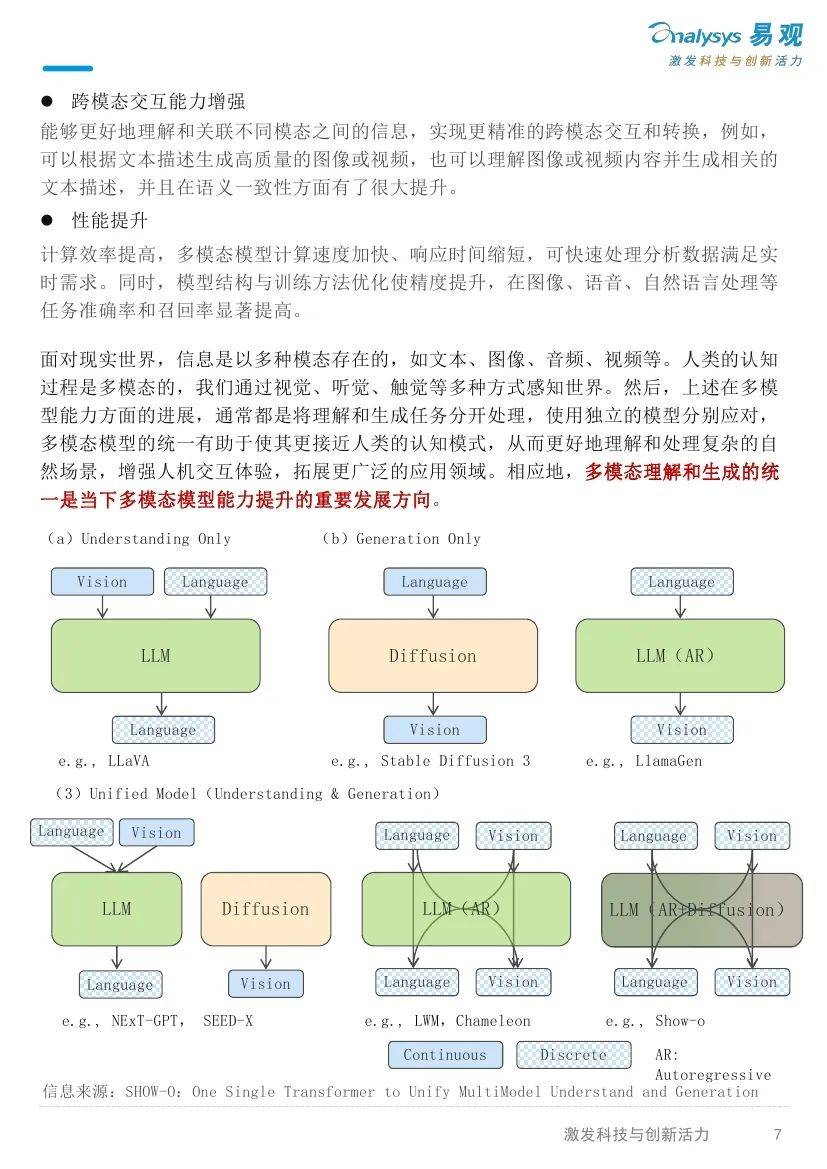
由此而开启Post-train阶段的Self-play RL(自对弈强化学习)范式对于后续大模型技术路线的升级和优化具有指引性的意义,传统预训练依赖全网语料,数据有噪声且质量不一,RLHF后训练受人类标注数据限制。纯强化学习(RL)方法无需人类标注数据,能让模型自我探索学习,激发创新和探索能力,利于突破未知领域。
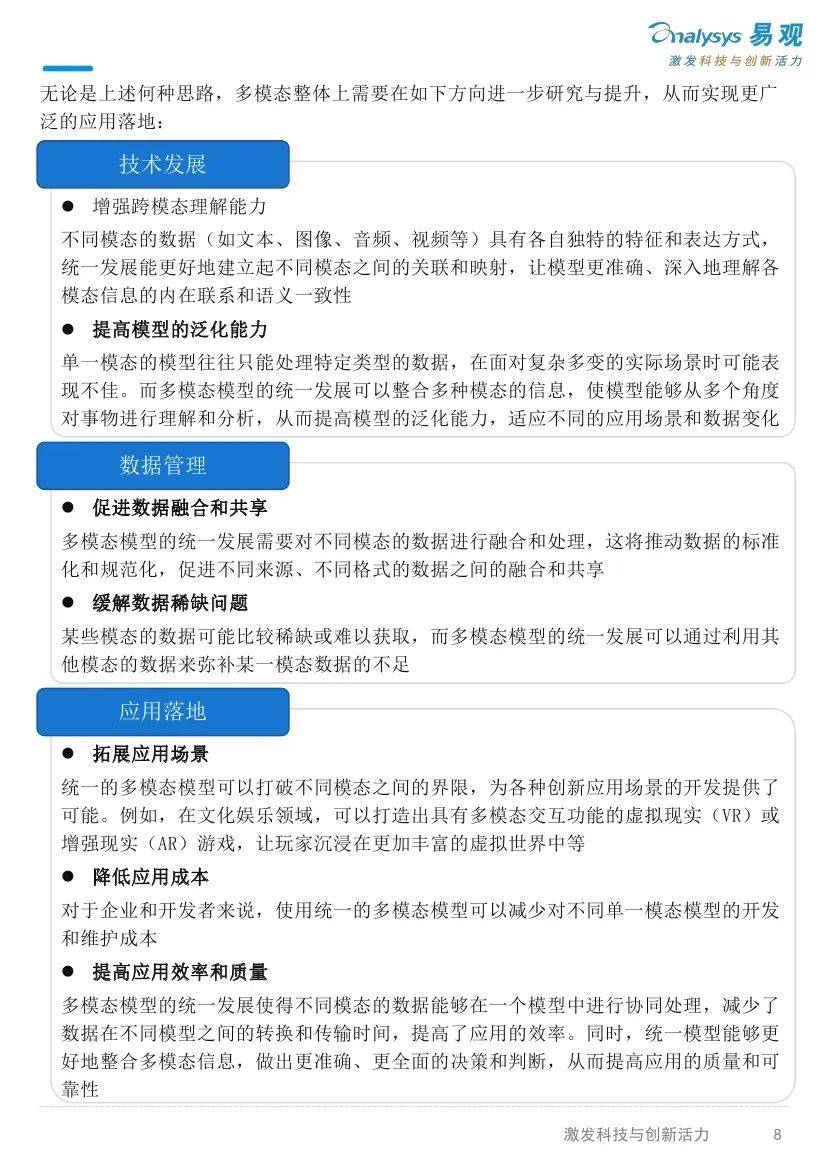
同时,也需要注意到,尽管Self-play方法已经开始在一定范围内得到应用,但是,也仍然存在挑战需要进一步研究和解决,包括收敛性问题、环境非平稳性问题、可扩展性与训练效率等问题。另外,强化学习注重设计良好的“奖励模型”,但是除了数学、代码等理科领域,强化学习在其他领域仍然难以泛化。



















声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
